Following the success of Large Language Models (LLMs), Large Multimodal Models (LMMs),
such as the Flamingo model and its subsequent competitors, have started to emerge as natural
steps towards generalist agents. However, interacting with recent LMMs reveals major limitations that
are hardly captured by the current evaluation benchmarks. Indeed, task performances (\emph{e.g.}, VQA accuracy)
alone do not provide enough clues to understand their real capabilities, limitations, and to which extent
such models are aligned to human expectations.
To refine our understanding of those flaws, we deviate from
the current evaluation paradigm and propose the EvALign-ICL framework
(Beyond Task Performance: Evaluating and Reducing the Flaws of Large
Multimodal Models with In-Context Learning), in which (1) we evaluate 10 recent open-source LMMs from 3B up to 80B parameter scale, on 5 different axes; hallucinations,
abstention, compositionality, explainability and instruction following. Our evaluation on these axes
reveals major flaws in LMMs.
While the current go-to solution to align these models is based on training, such as instruction tuning or RLHF,
we rather (2) explore the training-free in-context learning (ICL) as a solution, and study how it affects these limitations.
Based on our ICL study, (3) we push ICL further and propose new multimodal ICL approaches such as;
Multitask-ICL, Chain-of-Hindsight-ICL, and Self-Correcting-ICL.
Our findings are as follows.
(1) Despite their success, LMMs have flaws that remain unsolved with scaling alone.
(2) The effect of ICL on LMMs flaws is nuanced; despite its effectiveness for improved explainability, answer abstention,
ICL only slightly improves instruction following, does not improve compositional abilities, and
actually even amplifies hallucinations. (3) The proposed ICL variants are promising as post-hoc approaches to
efficiently tackle some of those flaws.
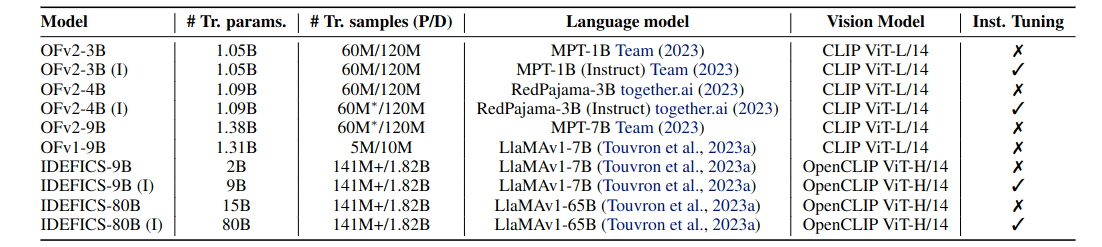
We consider 10 different models from OpenFlamingo (OF) and IDEFICS (up to 80B parameters) as described in the table below
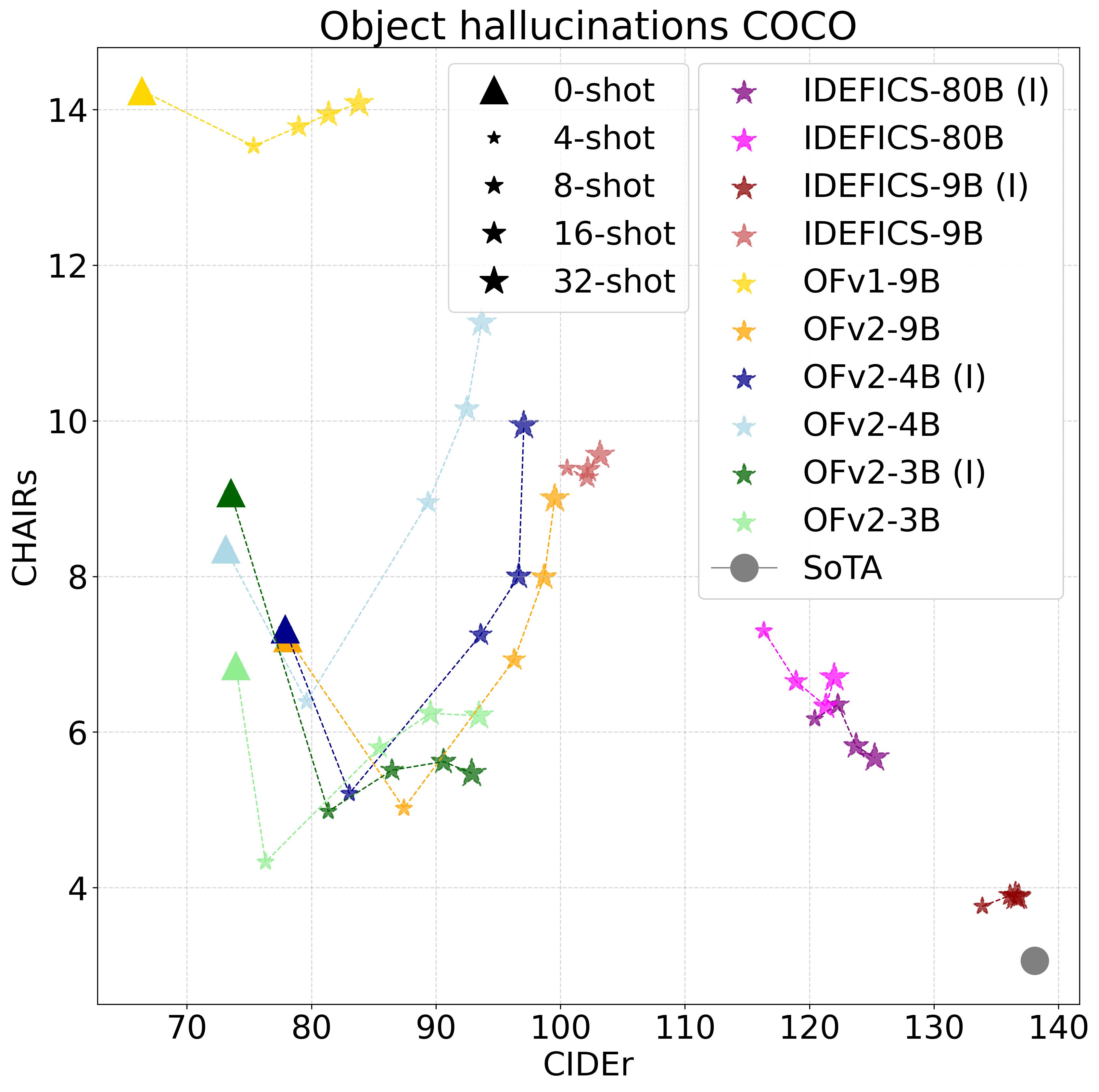
Hallucinations in text is the tendency of LLMs to generate coherent plausible responses, over factual ones.
By analogy, when considering multiple modalities, we are also concerned with object
hallucinations (OH) wherein the textual description generated by multimodal models describe objects not present in the input image.
Addressing OH is critical to avoid any harm, especially in critical applications (\emph{e.g.} autonomous
driving or medical imaging). We evaluate the various LMMs for captioning on the COCO dataset. Overall accuracy is measured
with CIDEr. In addition, to capture OH, we report the CHAIRs metric
comparing the objects referred in the generated captioning to those actually in the image.
Finding 1. LMMs suffer from severe hallucinations. A small number of ICL shots partially alleviate it, while increasing them exacerbates the problem, especially for small models (less than 9B params.).
Pretraining on more high-quality data and unfreezing the LLM weights helps to reduce hallucinations.
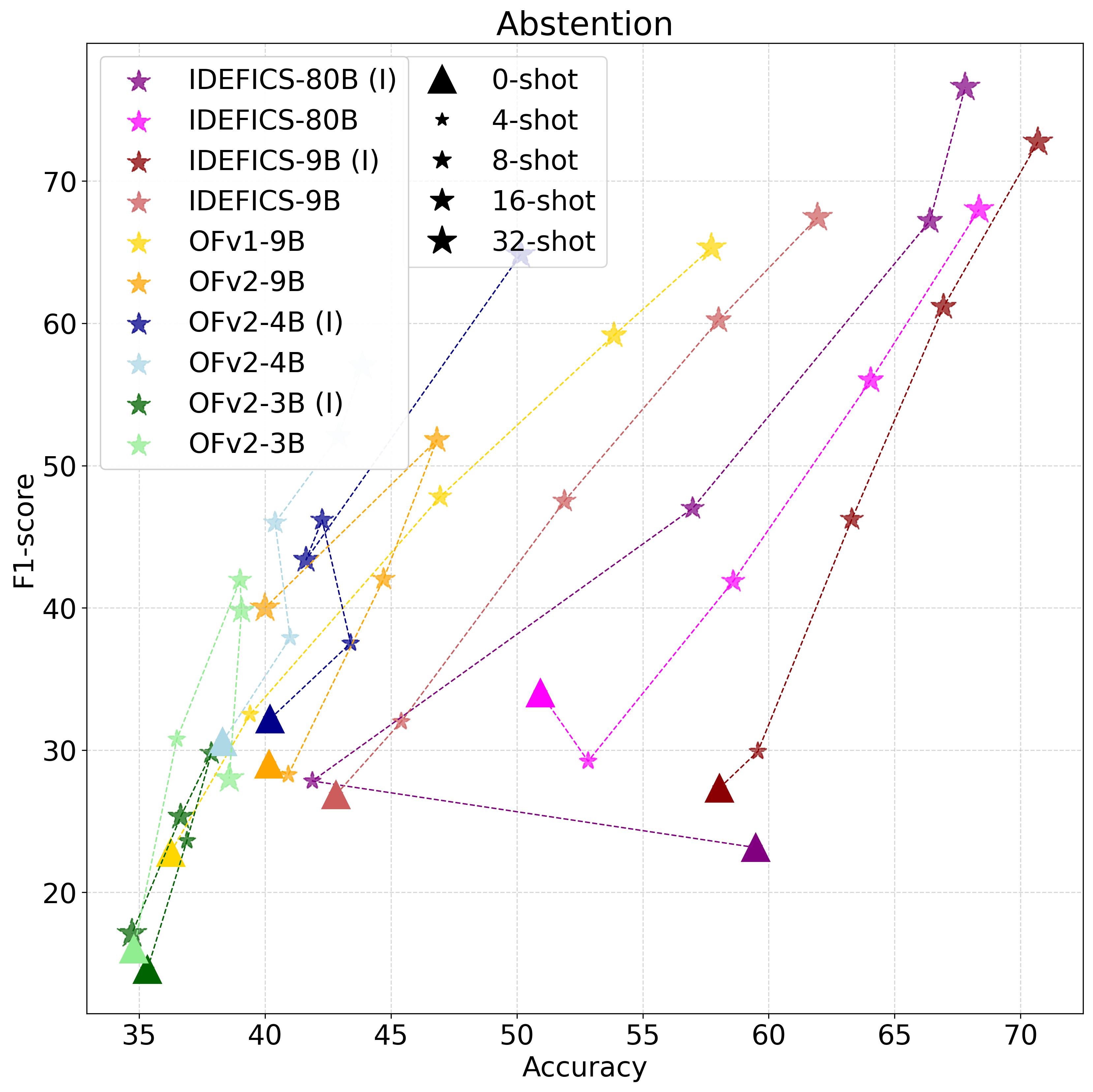
LMMs should know when they do not know, and abstain instead of providing incorrect answers.
Here we study a scenario where the question can not be answered from the image. We evaluate on TDIUC,
a VQA dataset containing absurd questions ($\sim22\%$ of a total number of questions), that are not related to
the image and thus should not be answered. In case of abstention, the model should generate a specific keyword.
We report the overall accuracy in addition to the F1-score abstention metric (absurd question or not).
Finding 2. LMMs give more likely incorrect answers than abstaining.
ICL helps them abstain. Larger models, better quality data, and unfreezing LM weights improve abstention.
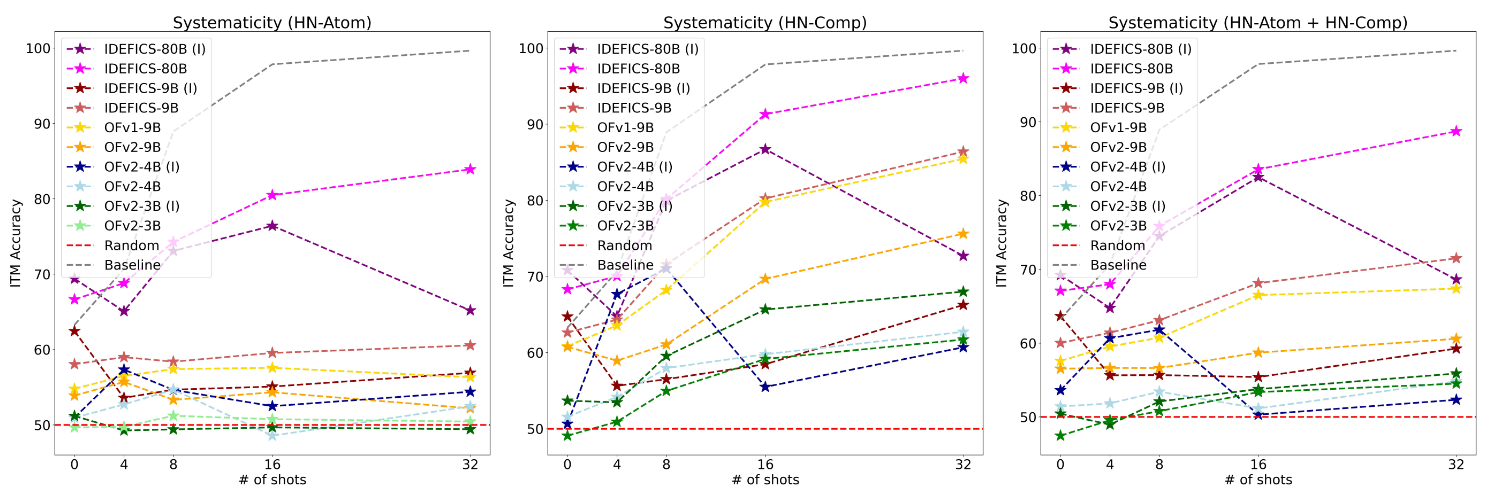
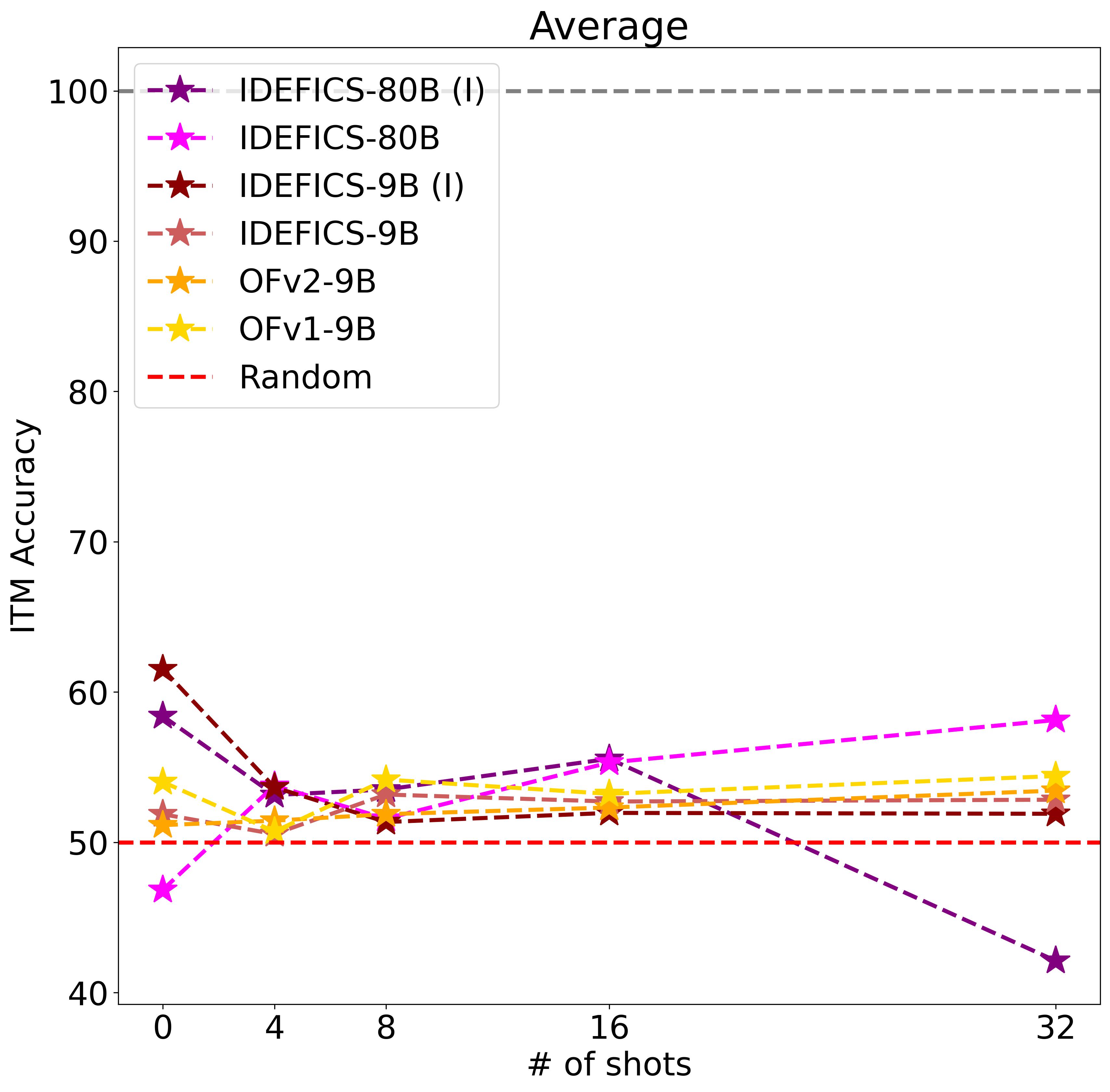
Compositionality exists when the meaning of a sentence is determined by its elements, and the rules to compose them.
To study this, we evaluate if LMMs' understanding of a caption is changed when changing its constituents.
We evaluate on the CREPE benchmark; an image-text retrieval dataset with hard negatives, constructed by
changing the composition of the ground truth captions. Instead of retrieval, we create the task of
Image-Text Matching (ITM). For ITM the model is given one caption and asked to decide if it describes the
image or not. We use the positive and negative captions provided by the benchmark.
Finding 3. LMMs lack compositional ability and struggle to acquire them even with ICL.
Despite the impressive abilities of LMMs, it is still unclear if generations are caused by some underlying
complex reasoning based on the input image, or rather on some memorization or bias exploitation. Instead of looking at
internal activations and learned features as means of output explanation,
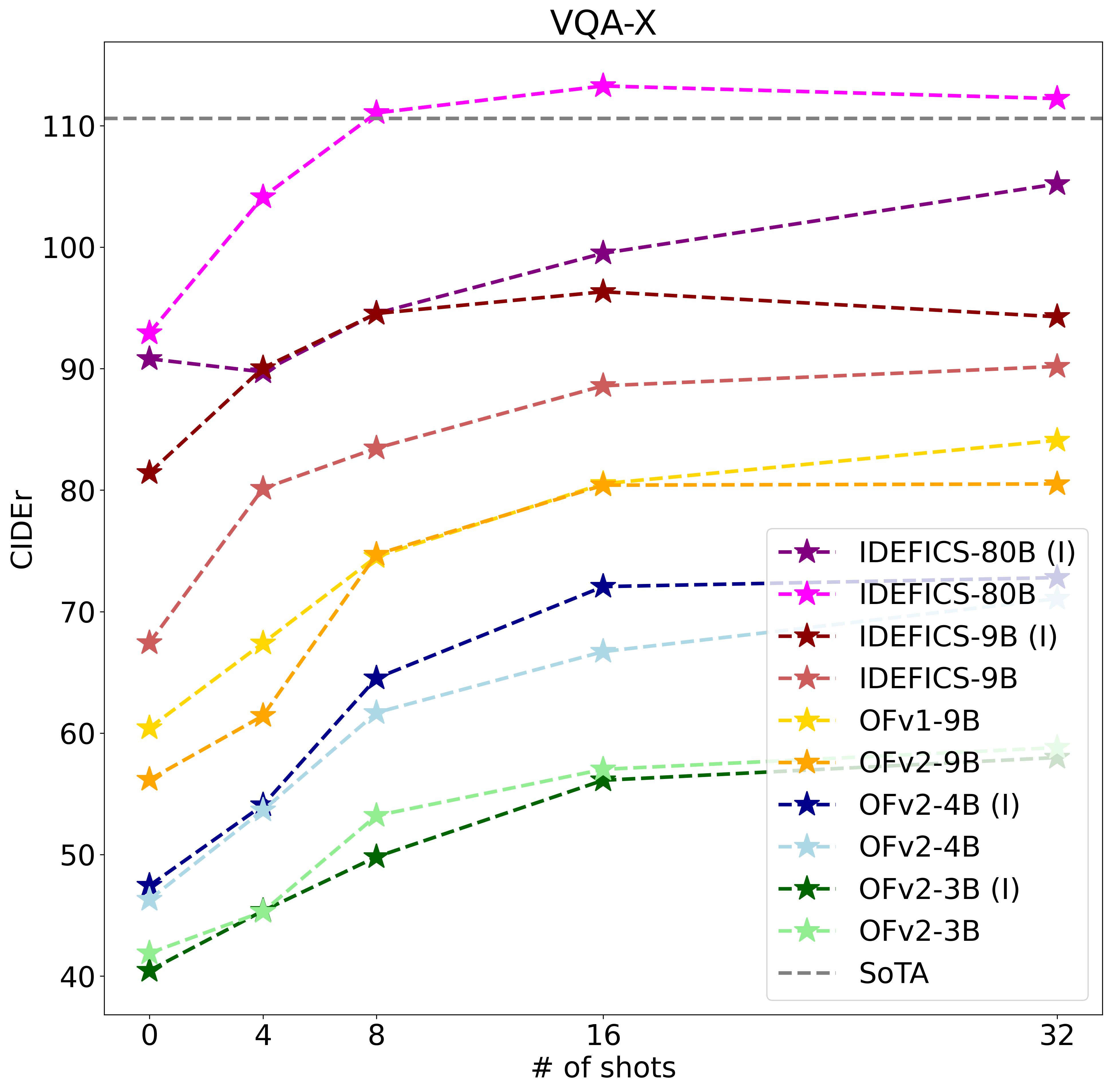
we try another and more explicit approach; by asking the model itself for an explanation. We consider VQA-X,
a VQA dataset with human-annotated explanations for each image-question-answer triplets, and CIDEr as
the metric to measure the syntactic similarity between the generated explanations and the ground truths.
Finding 4. LMMs still fail to provide good explanations, yet ICL can improve performances. Bigger models explain better.
Existing multimodal models are trained to solve relatively simple tasks, such as providing shallow image
descriptions or answering questions with one or two words. These capabilities are not enough to build general
assistants that can engage in conversation with humans. Helpful assistants should help humans answer complex questions,
precisely following specific instructions and engaging in conversations. Current approaches
to integrate such abilities are based on instruction tuning,
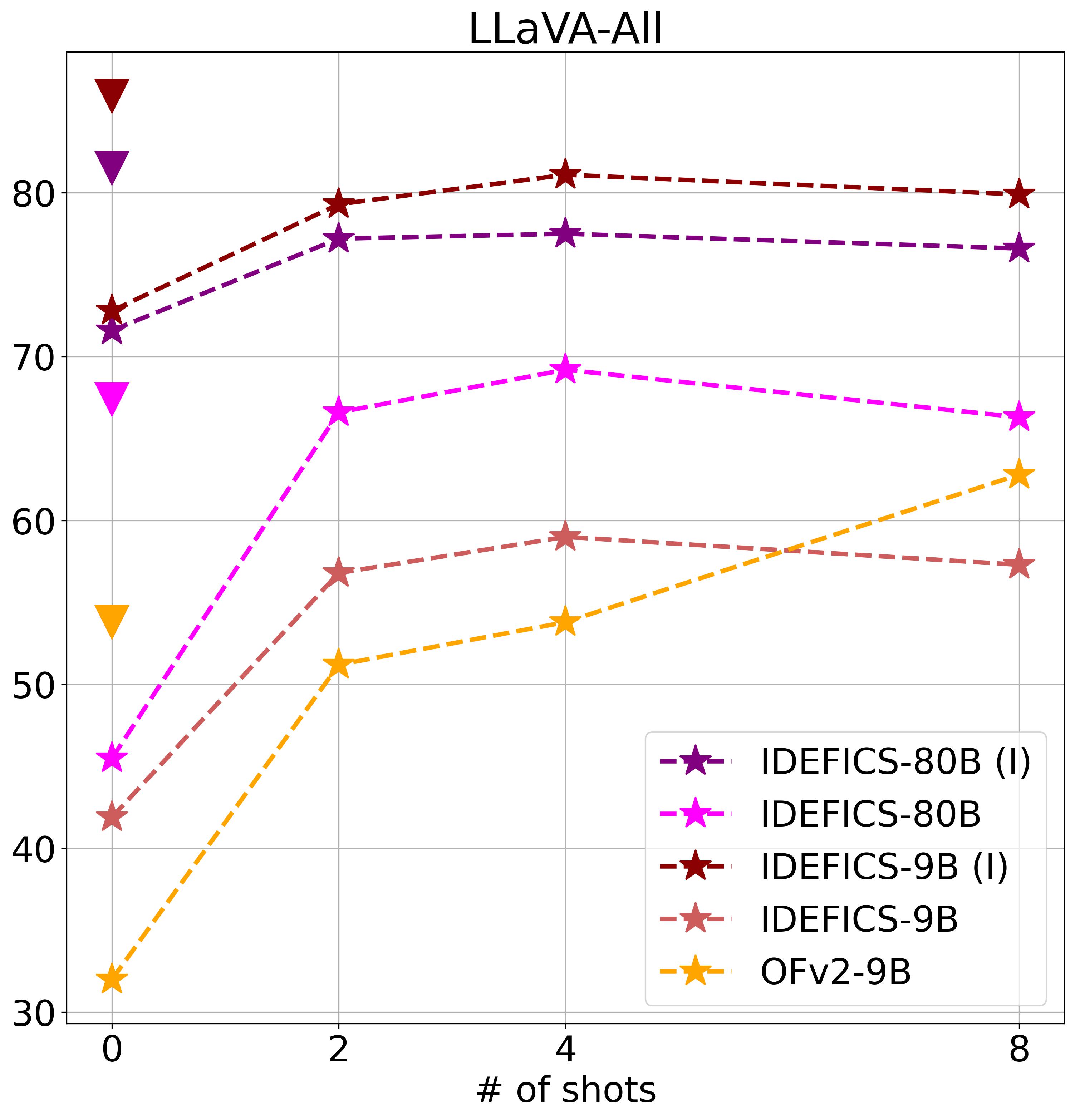
wherein the model is fine-tuned on curated instruction datasets. We evaluate LMMs on the LlaVA dataset,
which contains 3 types of instructions; giving detailed image descriptions, and answering
complex questions and conversations. These instructions are generated with GPT-4 (text-only). For ICL, the demonstrations
are selected randomly from the dataset with the same instruction type as the query.
Finding 5LMMs do not precisely follow user instructions, and small number of ICL demonstrations makes them slightly more helpful, especially with models that are not instruction tuned.

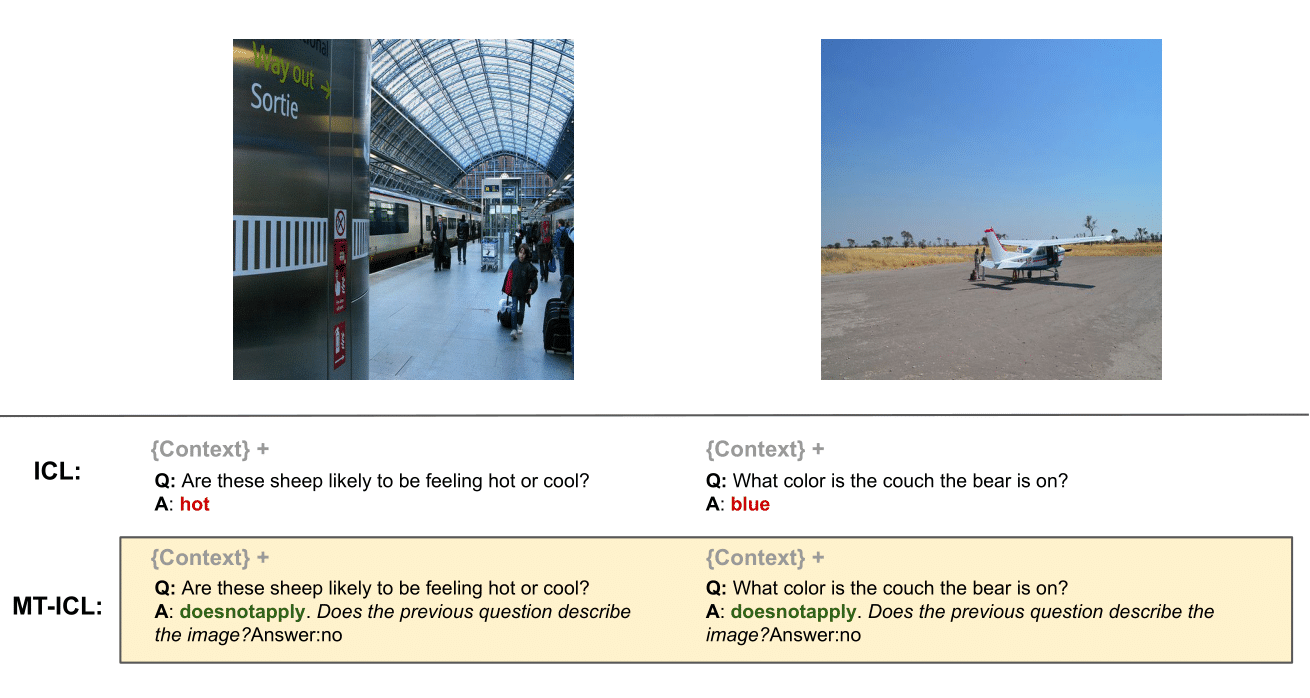
We push ICL further and propose new improved variants to address some of LMMs limitations


This work was partly supported by ANR grant VISA DEEP (ANR-20-CHIA-0022), and HPC resources of IDRIS under the allocation 2022-[AD011013415] and 2023-[AD011013415R1] made by GENCI. The authors would like to thank Hugo Laurençon for fruitful discussions.
@article{shukor2023beyond,
title={Beyond Task Performance: Evaluating and Reducing the Flaws of Large Multimodal Models with In-Context Learning},
author={Shukor, Mustafa and Rame, Alexandre and Dancette, Corentin and and Cord, Matthieu},
journal={arXiv preprint arXiv:2310.00647},
year={2023}
}
